
Twitter Stock Market Prediction
Description
In the year 2000, the value of all trades in US financial markets exceeded $500 Trillion (U.S. Census Bureau, 2001), over fifty times the GDP of the United States for that year. A third of all stock trades were driven by algorithms.
The Stock Market is greatly influenced by investor confidence and human emotion. This project analyzed 1% of the 250,000,000 million daily tweets for the past 100 days for human emotion in order to predict the stock market performance of various financial symbols.
Novelty: Our novel contributions are to experiment with identifying common pockets of sentiment using K-means clustering machine learning algorithms and drawing correlations to varied financial stocks and futures, as opposed to just a single index. There are few publications that accurately predict the stock market based on Twitter sentiment analysis. Those that claim to do so use questionable methods.
Functional Requirement: Predict whether a stock, index, futures contract, exchange traded fund (ETF), fixed-income security, indicator, or mutual fund will go up or down in a future time-frame (provide an uncertainty along with this prediction)
System Design
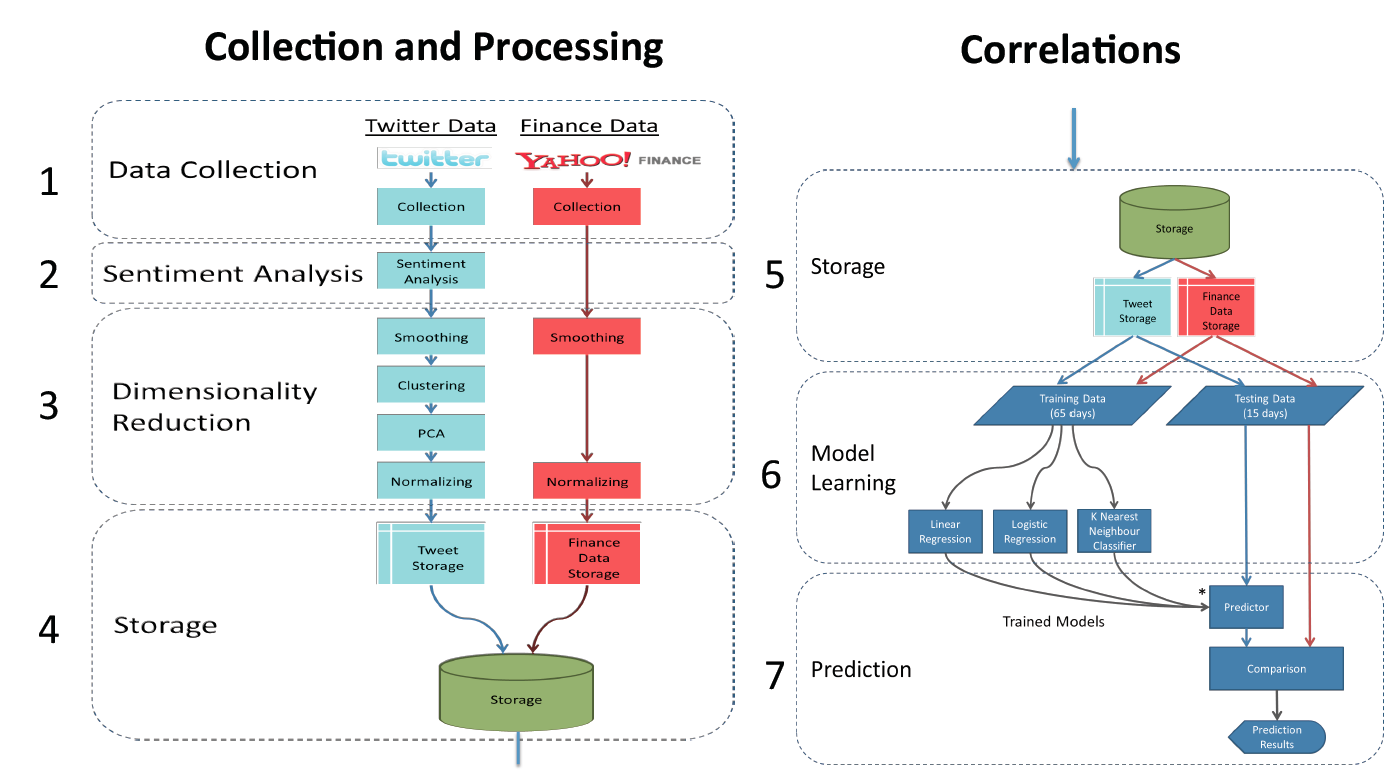
- Data Collection – Download 2.5 million tweets per day
- Sentiment Analysis – Analyzes each tweet for 13 dimensions of sentiment: Tension, Depression, Anger, Fatigue, Vigor, and Confusion, etc. Assigns each dimension a numeric score
- Dimensionality Reduction - extracts important and sometimes hidden signals of sentiment from the sentiment data
- Storage – MongoDB database stores 450GB of Tweets. Holds the raw tweets, sentiment scores, clustering results, financial data, and all other intermediate results
- Model Learning – The predictive models are learned that are used by the predictor to create the stock price predictions. Models are learned based on training data. Testing data is then used by the prediction module
- Prediction Module - uses the derived Twitter data to make predictions about the stock price on the test data, the second partition of data mentioned in model learning module section. Uses linear and logistic regression and K-nearest neighbors prediction algorithm
Results
- Tested 2747 financial symbols
- Training Data: October 22nd 2011 to December 26th 2011 (65 days)
- Testing data: December 27th to January 10th 2012 (15 days)
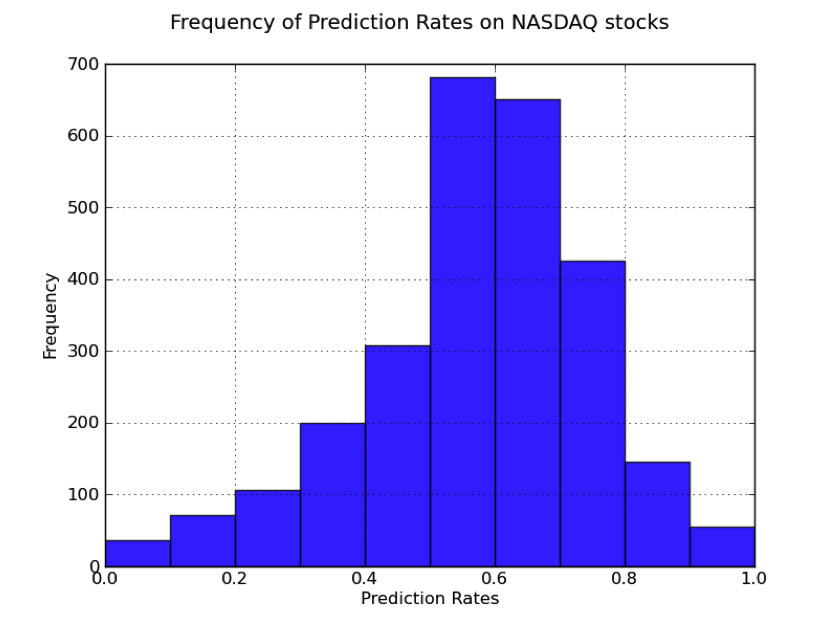
- When trying to predict a stock’s performance based on the number of tweets in each group, the average predictive rates were 54%
- Across all stocks, K-nearest Neighbor achieved 56% prediction rate across all offsets, and 57.2% prediction 1 day in advance
Technologies Used
Python, MongoDB, scikit-learn, Ubuntu Linux, University of Toronto ECE Servers
Awards
Outstanding Design Project of the Year in University of Toronto Electrical and Computer Engineering
More Information
In the News
In the University of Toronto Faculty of Applied Science & Engineering News:
April 9, 2012
Strolling through this year’s Electrical & Computer Engineering Capstone Design Showcase, it’s hard not to think, “Hey, there really is an app for that.” But you might just as easily discover there is also an algorithm for that.
The best fourth-year projects – as judged by the ECE faculty – included apps for lonely GO Train commuters and shoppers eager to escape lineups by paying via smartphone before leaving the store. The showcase also featured algorithms to speed the process of bioengineering microRNA for treating genetic disease, as well as algorithms to predict the stock market, using 250 million daily tweets.
The April 5 event, which took place at the Bahen Centre atrium, showcased just 15 of a possible 100 projects.
“These projects tend to be very well executed or use technologies that are interesting, or not straightforward,” said Dr. Phil Anderson, Senior Lecturer in The Edward S. Rogers Sr. Department of Computer & Electrical Engineering. “In other years, several have gone on to get patents.”
Certainly, Sumanth Ravipati (CompE 1T2) and Thisal De Silva (CompE 1T2) would like to see their GO Train commuter app become so popular that they might one day charge for it. Right now, anyone can download it for free at Apple’s App Store.
Their inspiration comes from the newspaper t.o.night, whose popular ‘Shout Out’ feature posts commuters’ complaints, questions and requests.
“Every day you see the same faces on the train, but nobody talks to each other. They prefer hiding behind shout outs,” said De Silva. “So we thought why not put it on a platform and let them reply in real time, so they don’t have to wait a day.”
The app also allows for private chats between commuters, but only works when you’re actually on the train. “That way, you look forward to the commute,” said Ravipati.
Alex Litoiu (CompE 1T2) and his project partner Mike Del Balso (ElecE 1T2) are also harnessing social media, but with a different goal in mind. Their system for analyzing global patterns of emotion on Twitter predicts whether stocks will go up or down.
The pair’s algorithm analyzes tweets from around the world for a list of words other researchers have correlated to emotions.
Litoiu and Del Balso tested their system over three months. They discovered they could predict with 57% accuracy – on average – whether a given stock in the NASDAQ Stock Market would go up or down 24 hours after analyzing the previous day’s tweets.
“So for a certain stock, we might have 100% accuracy, for others 30%. When we average those numbers across all stocks we are doing much better than random,” said Litoiu.
Judging from the crowds around their display, and the constant stream of questions, they aren’t the only ones intrigued by their algorithm’s potential.